In Learning Perl, we tell readers to use the & to prefix subroutine calls when we introduce the idea of reusable code. This doesn’t sit well with some programmers because it’s not how the experienced programmers work. The & does some magic, which we don’t mention in the book, and it’s a bit crufty for the Perl 5 programmer. Continue reading “Why we teach the subroutine ampersand”
“at least two or three hours per week”
Randal Schwartz, in his interview with Leo Laporte and Chris DiBona on FLOSS #9 (way before Randal was ever the host of the same show), says around the 9:20 mark that “Perl is meant for people who use the language at least two or three hours per week”.
This remark was highlighted by John D. Cook in Three-hour-a-week language. I found an even better thought in the comments. rdm says it’s more about knowing what to look for:
I have enough of a perl vocabulary that I know how to perform relevant searches when I am reaching for a concept. Python? Not so much…
That doesn’t have much to do with the language, really. If you spend a couple of hours each week using a language, reading the docs, and looking for answers, you gain experience and knowledge about the process making it slightly easier the next time. I’m not a great programmer, but I’m a pretty good answer finder. That can make up for a lack of talent.
In my Learning Perl classes, I tell people they aren’t going to learn Perl in a week. I can make them aware of things, but they need to practice. Even though we do exercises in the class, thinking about Perl all day for four days can melt anyone’s brain. Take that three (or more) hours a week for half a year and you’ll probably get passably good.
I got used to Perl by doing it almost every day all day for two years, but then I had to relearn it when Randal trained me to be a Perl trainer. I actually learned more by answering the random questions that people had. That was either students in classes or conversations on usenet. Now that could be Stackoverflow. You create some common set of problems for yourself, but by reading the problems from many people, you get to learn things from problems you wouldn’t make yourself. That’s where the gold is.
Advice to a new Perl user
A Learning Perl reader asked me for some advice in private email. After I typed it out I felt like posting it for everyone. He graciously let me use his questions and my answers.
1. I wish to use Perl on Windows, is it a good combination (from a career perspective)?
Although Windows can be a pain, and not just because of Perl, there are plenty of people who need to get things done on Windows. With the Win32:: modules, you can hook into the same APIs. I think you can even use Perl from Powershell.
2. Would the knowledge I’ll gain after self-training for Perl be useful for a long time?
You always have to keep learning. Perl is just a language and you can get almost anything done with it, but the more valuable thing is knowledge about the problem you’re trying to solve.
“Useful” is a harder thing to judge because it mostly depends on what you are doing. Perl can do quite a bit, but I find that “useful” is related to what non-Perl libraries I can access through Perl.
I don’t think you can go wrong at least learning Perl and practicing it for a couple of years. Some of the experience you gain there you can transfer to another language. It’s same the other way around, too, since the more experience you have as a programmer the easier new languages should be for you.
3. How does one figure out a niche for himself in this hugely spread-out world of Perl?
I find something that’s not getting done and take ownership of it. Something out there is being neglected. Just keep plugging away at something boring and unexciting. Running a local user group is good for that.
“The stat preceding -l _ wasn’t an lstat”
I ran into a fatal error that I haven’t previously encountered and I couldn’t find a good explanation where I expected it. The -l file test operator can only use the virtual _ filehandle if the preceding lookup was an lstat.
The file test operators, all documented under the -X entry in perlfunc, can use the virtual filehandle _, the single underscore, to reuse the results of the previous file lookup. They don’t just look up the single attribute you test, but all of it (through stat) which it filters to give you the answer to the question that you ask. The _ reuses that information to answer the next question instead of looking it up again.
I had a program that was similar to this one, where I used some filetest operators, including the -l to test if it’s a symbolic link.
use v5.14;
my $filename = join ".", $0, $$, time, 'txt';
my $symname = $filename =~ s/\.txt/-link.txt/r;
open my $fh, '>', $filename
or die "Could not open [$filename]: $!";
say $fh 'Just another Perl hacker,';
close $fh;
symlink $filename, $symname
or die "Could not symlink [$symname]";
# http://perldoc.perl.org/functions/-X.html
foreach( $filename, $symname ) {
say;
say "\texists" if -e;
say "\thas size " . -s _ if -z _;
say "\tis a link" if -l _;
}
I get this fatal error:
The stat preceding -l _ wasn't an lstat at test_link_test.pl line 19
The entry in perlfunc doesn’t say anything about this, but it hints that -l is a bit special:
If any of the file tests (or either the stat or lstat operator) is given the special filehandle consisting of a solitary underline, then the stat structure of the previous file test (or stat operator) is used, saving a system call. (This doesn’t work with -t , and you need to remember that lstat() and -l leave values in the stat structure for the symbolic link, not the real file.) (Also, if the stat buffer was filled by an lstat call, -T and -B will reset it with the results of stat _ ).
Adding the diagnostics pragma has the answer that isn’t in perlfunc:
The stat preceding -l _ wasn't an lstat at test_link_test.pl line 19 (#1)
(F) It makes no sense to test the current stat buffer for symbolic
linkhood if the last stat that wrote to the stat buffer already went
past the symlink to get to the real file. Use an actual filename
instead.
The other file test operators will perform a stat. If the file is a symlink, the stat follows the symlink to get the information from its target. A symlink to a symlink will even keep going until it ultimately gets to a non symlink. With a stat, the -l _ will never be true because it always ends up at the target, even if it doesn’t exist.
The lstat doesn’t follow the link, so it can answer the -l _ question because it might have returned the information for a link and in the case of a non-link, it works just like stat.
As the long version of the warning says, it’s probably better to never use the _ filehandle and use the full filename instead. Sure, it has to redo the work, but you won’t be surprised by a fatal error if you did the wrong type of lookup before.
Learning Perl Challenge: Remove intermediate directories
I often run into situations where I have directories that contain only one file, a subdirectory, with contain only one file, a subdirectory, and so on for a long chain, until I get to the interesting files. These situations come up when I have only part of a data set so the files that would be in other directories aren’t there, and I find it annoying to deal with these long directory specifications. So, this challenge is to fix that by collapsing those one-entry directories into a single one.
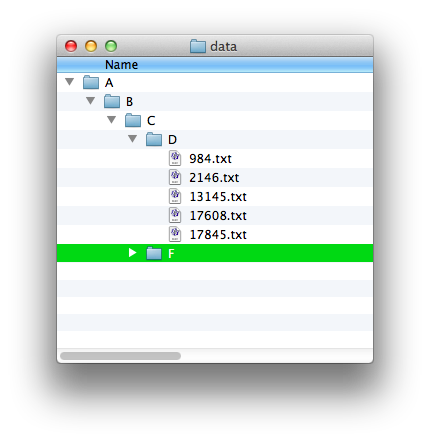
For example, you should take this structure, where you have A/B/C/D/E in a direct line with no other branches:
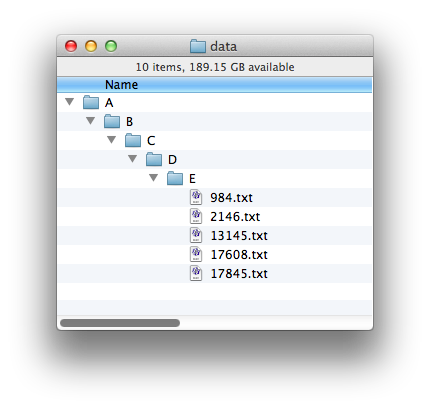
and turn it into this one, with a single directory with the files that were at the end:
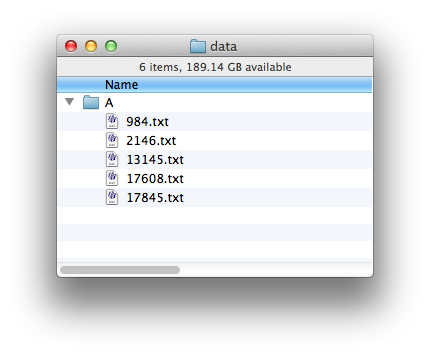
However, you should only moves files up if the directory above it has only one entry (which must be a subdirectory!). In this example, A/B/C has two subdirectories in it:
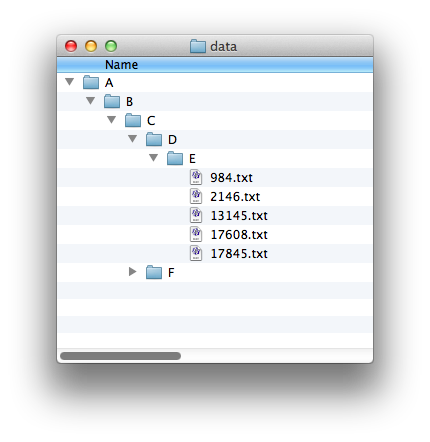
so the the files in E should only move up into D. Otherwise, the files from the two branches in C would get mixed up with each other.